As businesses generate a large amount of data in today's data-driven world, businesses must extract, transform, and load data from various sources. Extract, transform, load (ETL) refers to the three interconnected data integration processes that extract and move data from one database to another.
An ETL pipeline is the most popular method for effectively processing large amounts of data. This blog delves more into building an effective ETL pipeline process and different ways to build an ETL pipeline.
Understanding ETL Pipeline and its Significance
With the advent of cloud technologies, many organizations are transferring their data using ETL tools from legacy source systems to cloud environments. The data extraction, transformation, and loading (ETL) pipeline consists of tools or programs that take the data from the source, transform it according to business requirements, and load it to the output destination, such as a database, data warehouse, or data mart for additional processing or reporting. There are five types of ETL pipelines:
● Batch ETL pipeline - Useful when voluminous data is processed daily or weekly.
● Real-time ETL pipeline - Useful when data needs to be quickly processed.
● Incremental ETL pipeline - Useful when the data sources change frequently.
● Hybrid ETL pipeline - A combination of batch and real-time ETL pipeline, it is useful when there is a need for quick data processing but on time.
● Cloud ETL pipeline - Useful when processing the data stored in the cloud.
Methodology to Build an ETL Pipeline
Here are the steps to build an effective ETL pipeline to transform the data effectively:
1. Defining Scope and Requirements - Defining the ETL data and data points before beginning the building process is essential. Moreover, identify the source system and potential problems, like data quality, volume, and compatibility issues.
2. Extract Data - Using an API system, which includes SQL queries or other data mining tools, extract the data from the source system.
3. Data Manipulation - The extracted data is often not in the desired format. So, transform the data by cleaning, filtering, or merging it to make it suitable for achieving the desired goal.
4. Data Load - Now, load the modified data into an endpoint file storage system by creating schemas or tables, validating mapping fields and data, and managing the errors.
5. Testing and Monitoring - After installing the ETL pipeline, thorough testing is essential to ensure it works perfectly. Moreover, keep monitoring the ETL operations to resolve the errors during its functioning.
6. Iterate and Improve - The last step aims to update the ETL pipeline to continue meeting the business needs by optimizing it, adding new data sources, or changing the target system.
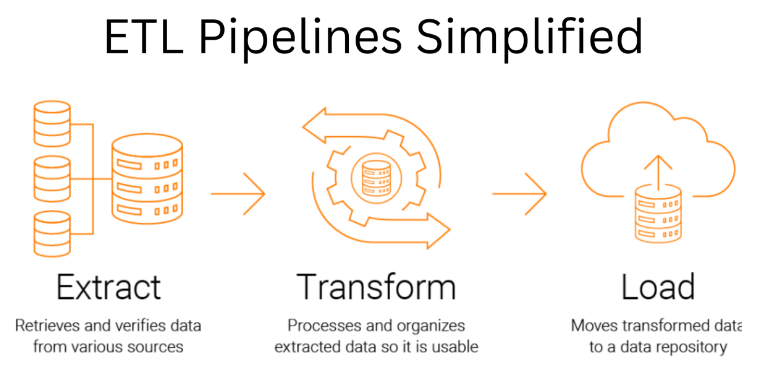
Different Phases of ETL Process
Extraction, Transformation, and Loading are different phases of the ETL process, and here's how each phase contributes to enhancing the data quality:
● Extraction
Data is collected from various data sources during the "extract" stage of ETL data pipelines, where it eventually appears as rows and columns in your analytics database. There are three possible and frequently employed methods:
1. Full Extraction: A complete data set is pulled from the source and put into the pipeline.
2. Incremental Extraction: Only new data and data that has changed from the previous time are collected each time a data extraction process (such as an ETL pipeline) runs.
3. Source-Driven Extraction: In source-driven extraction, the ETL systems receive notification when data changes from the source, which prompts the ETL pipeline to extract the new data.
● Transformation
Data transformation techniques are required to improve the data quality. It is an important step for developing ETL data pipelines because the value of our data depends entirely on how well we can transform it to suit our needs. Following are a few illustrations of data processing steps to transform the data.
1. Basic Cleaning: It involves converting data into a suitable format per the requirements.
2. Join Tables: It involves merging or joining multiple data tables.
3. Filtering: It involves filtering relevant data and discarding everything else to increase the data transformation process.
4. Aggregation: It involves summarizing all rows within a group and applying aggregate functions such as percentile, average, maximum, minimum, sum, and median.
● Loading
The process of building ETL data pipelines ends with the loading of data. The final location of the processed data may differ depending on the business requirement and analysis needed. The target databases or data warehouses to store processed data include the ones mentioned below.
● Flat Files
● SQL RDBMS
● Cloud
Best Practices to Build ETL Pipelines
Here are expert tips to include while building ETL pipelines:
● Utilize ETL logging to maintain and customize the ETL pipeline to align with your business operations. An ETL log keeps track of all events before, during, and following the ETL process.
● Leverage automated data quality solutions to ensure the data fed in the ETL pipeline is accurate and precise to assist in making quick and well-informed decisions.
● Remove all the unnecessary data and avoid using the serial ETL process all the time. The ETL pipeline generates quick and clean output with less data input.
● Set up recovery checkpoints during the ETL process so that if any issues come up, checkpoints can record where an issue occurred, and you do not have to restart the ETL process from scratch.
ETL Pipeline vs. Data Pipeline: The Differences
Data and ETL pipelines are used for moving the data from source to destination; however, they differ. A data pipeline is a set of processes to transfer data in real-time or bulk from one location to another. An ETL pipeline is a specialized data pipeline used to move the data after transforming it into a specific format and loading it into a target database or warehouse.
Data pipeline is an umbrella term, and ETL pipeline is a subset. Here is a table describing the difference between the data pipeline and the ETL pipeline:

Wrapping up,
An ETL pipeline is an important tool for businesses that must process large amounts of data effectively. It enables businesses to combine data from various sources into a single location for analysis, reporting, and business intelligence. AWS Glue, Talend, and Apache Hive are the best tools for building ETL pipelines. Companies can build scalable, dependable, and effective automated ETL pipelines that can aid business growth by adhering to best practices and utilizing the appropriate tools.
Mindfire Solutions can help you support ETL throughout your pipeline because of our robust extract and load tools with various transformations. Visit our website today and talk to our experts.
No comments:
Post a Comment